Scrapebox is a tool that's been around for many years and I'd be surprised if there is an SEO out there who is not using this tool. However, for the average user it can be quite a complex tool, hard to navigate and you will most likely be unaware how to pull the appropriate data you may be looking to scrape. So I've decided to provide an in-depth, FREE Scrapbox tutorial/guide that will hopefully help you with this. It has been broken down into sections so that you are not overloaded with all this information at the one time.
Introduction to Scrapebox
Scrapebox is often called the " Swiss army knife of SEO " and to be fair it probably is. The things this tool can do is unbelievable, an old tool that is just updated regularly but retains its very simple interface, this makes this tool one of the best even in 2017. Now you can get the tool from here, it costs $97 dollars. You often get people whining and moaning at the cost of a tool but for what this tool does it is very much worth the $97 dollars that they charge which gives you a lifetime licence. If you want a tool to provide data that is worth using then there is always going to be a cost as the developers have to constantly work on the tool to make it work and they cant provide that for FREE. Above is the interface you will see when you get Scrapebox it all looks simple and easy to use. I have made a video to show you what all of the options do which will give you an overview of exactly what Scrapebox can do for you.
Proxies
You can either download this directly onto your PC or you can use a VPS. Once you've downloaded it you'll need to buy yourself some private proxies. These are what Scrapebox will use to get the information from search engines. The problem here is that Google notices when it is being hit by the same IP address in quick succession. The way to combat this is to buy private proxies (only you have access to them) and these will rotate so Google won't pick up on them. Proxies can be bought from a few places, one place I'd recommend is: poweruphosting.com I recommend that you get at least 20 proxies to begin with, you can always add more later if you need more but this is a good amount to start with. Proxies are paid for monthly, every month the company you have used should send you a new list by email. Now you have your proxies it's time add them to Scrapebox. Your proxies can be saved directly onto Scrapebox through a simple copy and paste feature.
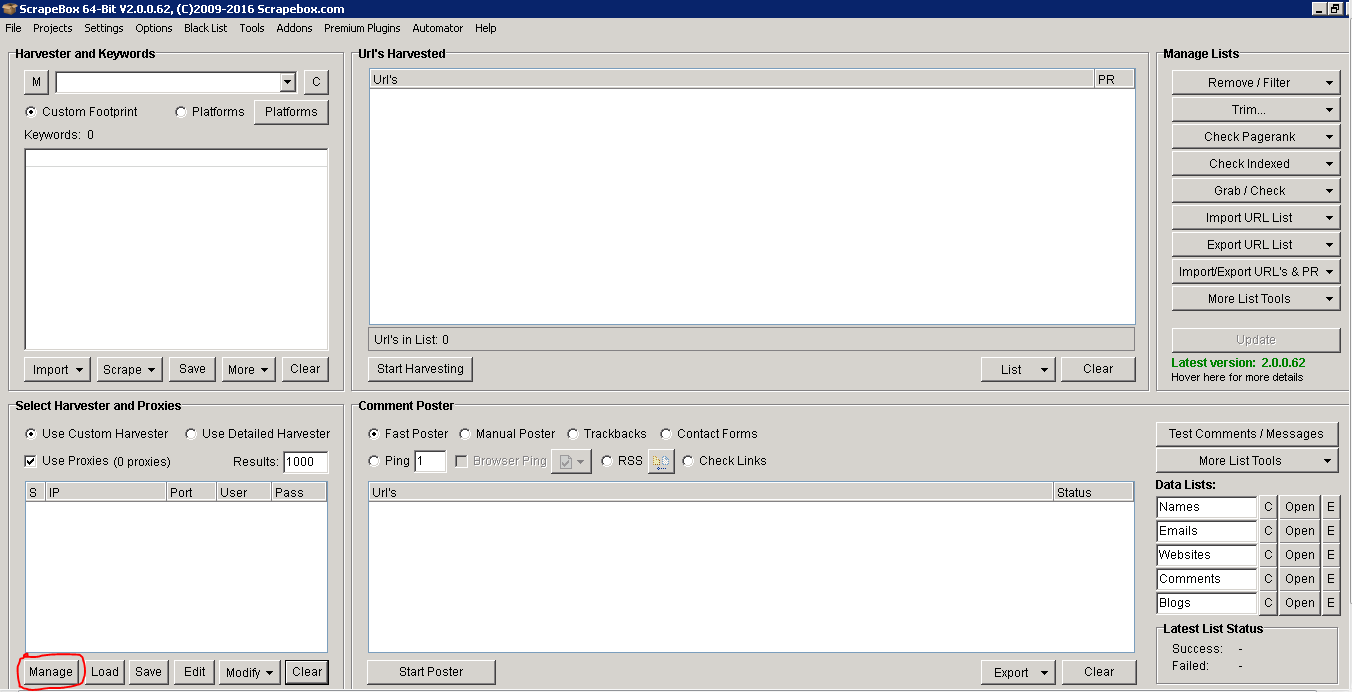
To save your proxies click on the 'manage' button at the bottom left of Scrapebox (highlighted in red in the picture above). This will open up a window that allows you to paste your proxies. There is an option to harvest proxies, this will find you a set of public proxies you can use but I would not advise this. Most public proxies have been abused and Google will blacklist them. When you purchase your proxies you will most likely receive them in a format like so: ipaddress:port:username:password. If this is the format you've received them in then go ahead and paste your proxies into Scrapebox. If not then you need to arrange them in this format for Scrapebox to accept them.
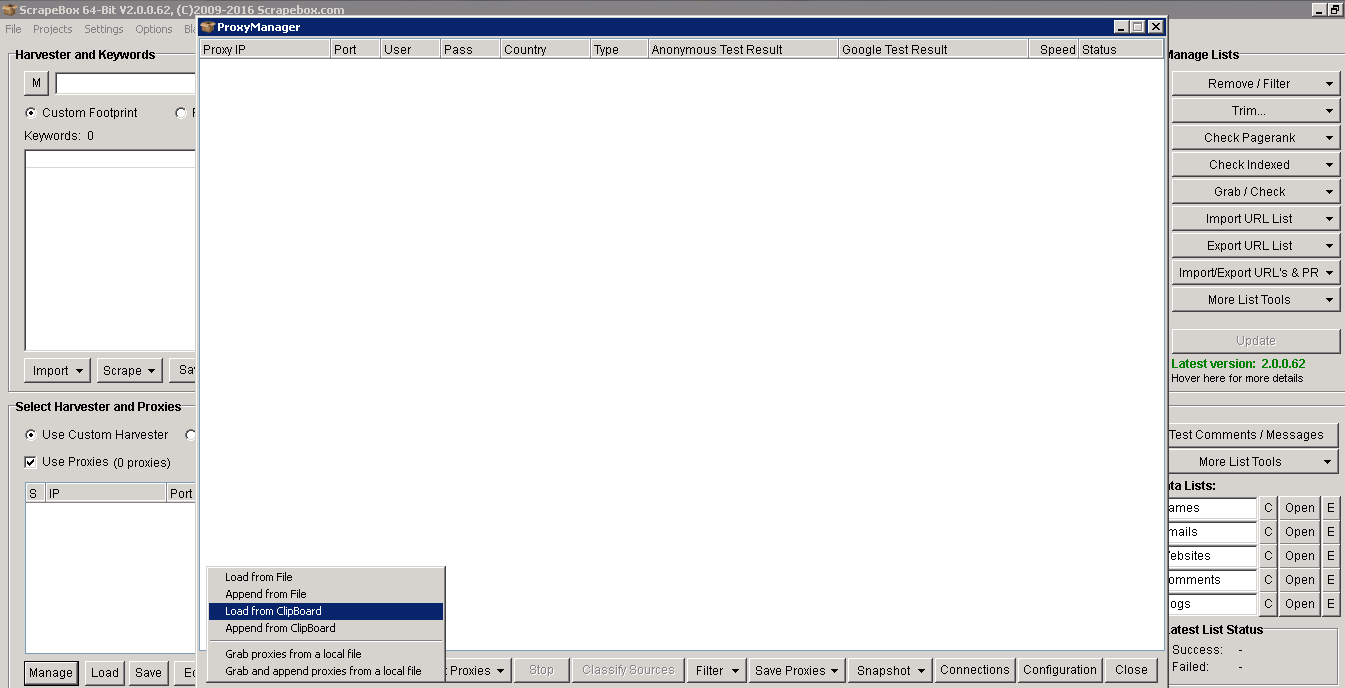
To add them, copy the proxies from the email that you received them in, click on the option that says 'load from clipboard'. Now all of your proxies will be in front of you, it's best to quickly test them.(If one or two fail, re-test failed proxies and they should be passed). Any proxies that pass will be highlighted in green and any that fail in red. One final thing is to filter out any that don't work with Google, any that don't work will be completely useless and will hinder your scrapes.

Once your happy with all the proxies on your list make sure you save them to Scrapebox.
Settings
Now your proxies are set, there are a few settings you can choose to adjust. For the most part all of the settings can be the default, if you have a lot of proxies you could adjust the amount of proxy connections that connect to Google. To do this head into the tab 'connections, timeout and other settings', If you are using 50 proxies then you should probably use somewhere between 5 - 10 connections.
Once the proxies are set you need to understand footprints before beginning any kind of scrape. The next topic is all about your Scrapebox footprints.
Footprints
Footprints regularly appear on webpages. For example the words "powered by WordPress" or "leave a comment", the first can be seen on a lot of site's using WordPress as it appears on it's default theme's and the second one can be seen on most blogs. This is what makes a footprint. If you were planning on finding WordPress site's to blog on then you can enter this footprint along with a few niche keywords and Scrapebox will find plenty of sites for you. What you want to begin doing is making your own good footprints. Having great footprints is key when using Scrapebox, these will give you the best results possible. Building your own takes a bit of time and research but once you've got a few good ones you can use them over and over again. When looking for footprints you can use some of these common operators: inurl:, intitle:, intext:
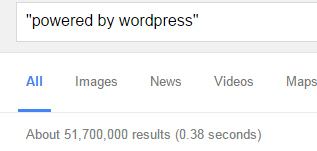
The best way to test your footprint is simply Googling it, now you can judge it by how many results appear. If it's only throwing up 1000-2000 results, then your footprint is useless. You need to try and find one that has a good amount of results before it becomes any kind of use to you.
Creating a list of footprints, separating them into different blog platforms etc is a good idea before you start scraping. Once you're happy you can begin putting them to the test. Now you've got a good set of footprints to use it's time to start scraping.
3. Scraping
When it comes to scraping you could carry out scrapes that take ten minutes or ones that take a day. This is where having a VPS comes in pretty handy as you can close it down and leave it running all day without it taking up any of your PC's power. If you do decide to run it locally you will only be able to run it on a windows PC. You also have the option to run it on parallels for your mac, but make sure you allocate your RAM appropriately if you choose to do so. Whenever you decide to start a scrape you need to make sure you plan out everything. A few factors you need to decide on are:
- The amount of proxies
- The amount of connections
- Amount of queries
- The speed of your Proxies
The default settings should be good to go, it's all about how many keywords you put in which will determine how long a scrape will run. Depending on whether you are using public or private proxies and how many you have, then you could change the number of connections you use. The next part is the keyword box.
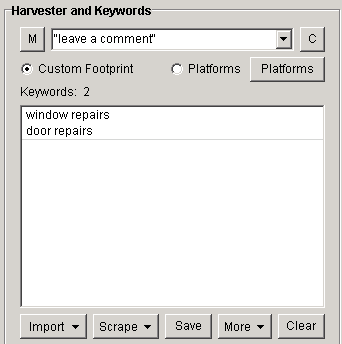
You can paste all of your keywords in here which will be used alongside your footprint. So if your footprint is simply "leave a comment" and you have a few keywords like "window repairs" and "door repairs", then your searches will look like this: "leave a comment" "window repairs" "leave a comment" "door repairs"
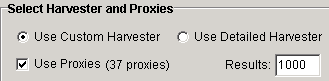
The next step is to make sure that you check the box that says "use proxies" otherwise the scrape won't run. You will also see in this section 'results'. This is quite a straightforward setting. This is the amount of results it will pull from each search engine, so if you're scraping only for a few sites you might want to choose 50 results for each of your keywords. However, if you're scraping for a massive amount of site's then you should use 1000 which is the maximum per keyword. The only problem here is that good footprints can have over 100,000 results. To narrow down your results to the best possible you have to start using stop words. For example if you search using the footprints "leave a comment" and "window repairs" you get over 30,000 results.
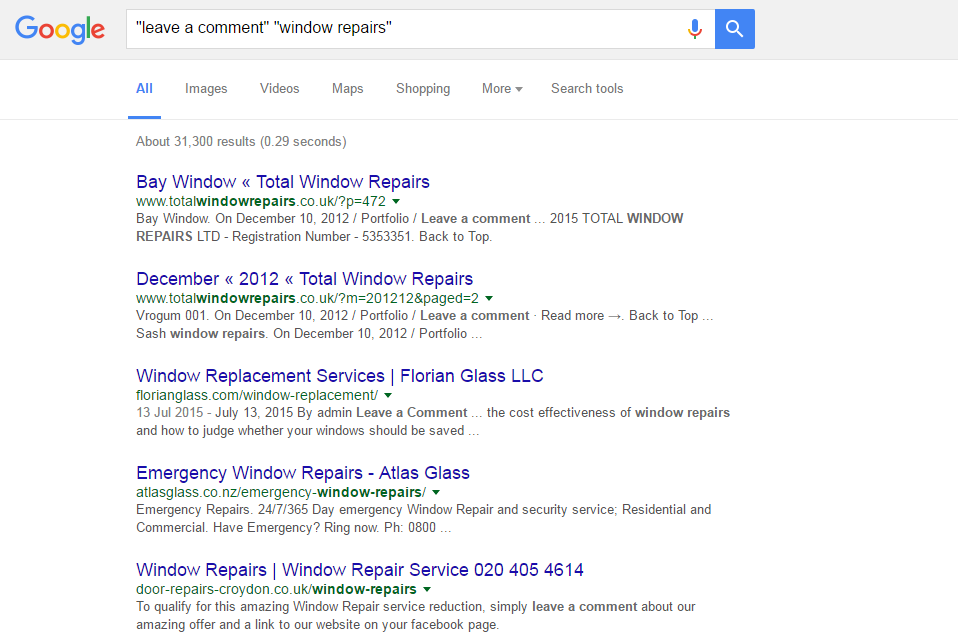
Now if we add the stop word "about" to the search then we get just over 20,000 results. These words allow you narrow down your search through Google's index so you can get exactly what you are looking for.
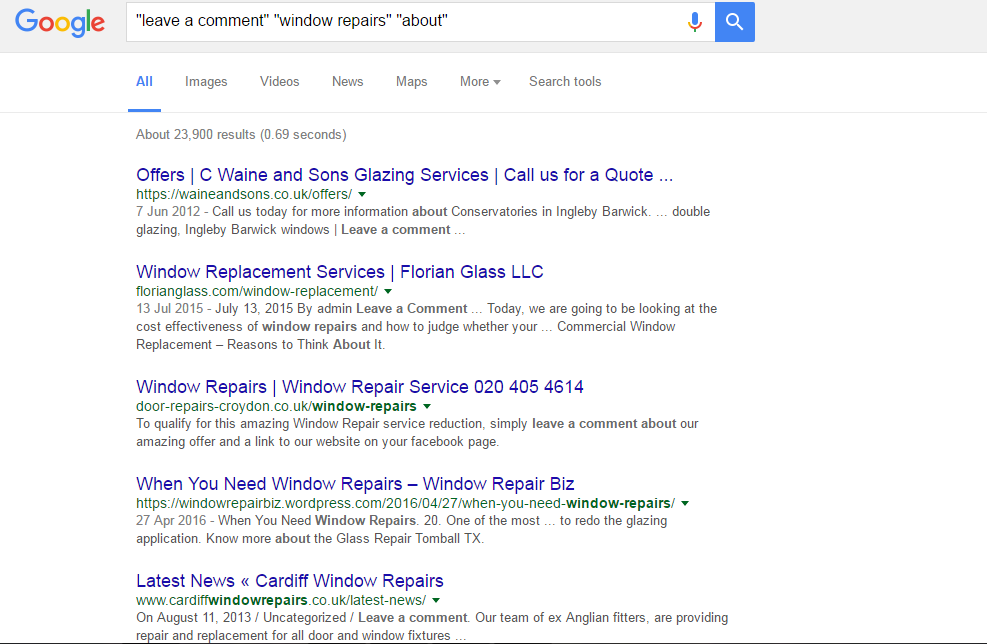
Here is an example of a few stop words you could use: "from" "get" "give" "make" "need" Now that you've got your footprints, keywords and stop words to go with them it's time to start your scrape. If you're running a scrape with a mass amount of keyword's then you should leave it running on your VPS to do its thing (If you're using your PC then you should run it overnight). When you come back it should be finished, showing you a full list of URLs that have been scraped. If your list hasn't finished scraping yet, you can leave it longer or stop it manually. If you do stop it you will be given a list of the keywords that have finished and which ones haven't. Any results that come back with nothing have either not been searched yet or no results were found.
Once you've stopped your scrape you can export all the uncompleted keywords so you can pick it up where you left off. Scrapebox can only have 1,000,000 results in its harvester at a time. It will automatically create a folder with a date and time that contains the 1,000,000 and continue onto the next few. This is great but there will be a really high number of duplicate URLs. This is easy to remove when you have a bunch of URLs under the harvester limit. You can do this by opening the 'Remove/Filter' section and removing duplicate domains and URLs, but if you're working with multiple files you'll need to use dupremove - it is a free Scrapebox add-on that can combine millions of URLs and remove any duplicate URLs and domains on all of the files.
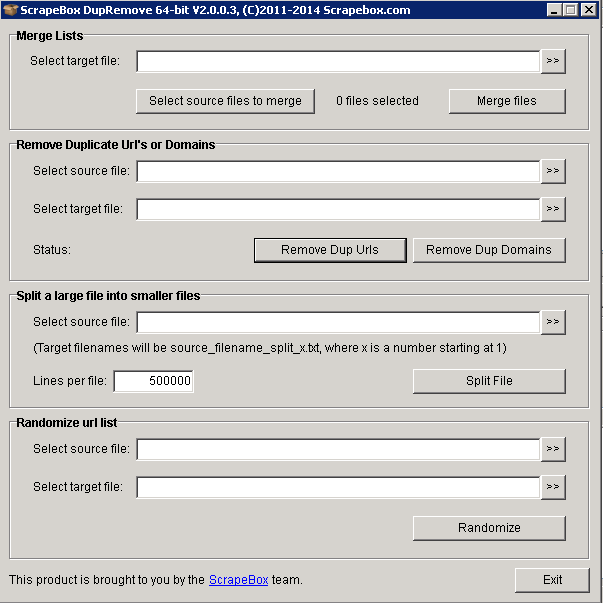
Dupremove also allows you to split your files into smaller files, which is a whole lot easier to manage. To begin using this you need to click on the 'Addons' tab and select 'Show Available Addons'. Scroll down to dupremove and install the add-on, now it's installed you'll see the window in the picture above. It's a really simple process, all you do is select the files containing the URLs which are found in the scrapebox harvester folder (also remember to export the existing list in the harvester to that file also). Merge the files and name it whatever you want. I call it 'merged list'. Then you add the list into the source file and name the new target file, which I would call 'final merged'. Now you can split the files up, setting the amount of URLs that you want per file.
Harvester
If you want to scan a site individually then you can enter the URL (including http://) into the custom footprint box and it will show you the whole list of all its pages. From here you can use the email grabber which I will show later on in the course or check for backlinks on the site. There are quite a few things you can do with your harvested URL list, a lot of the features are shown on the right hand side.
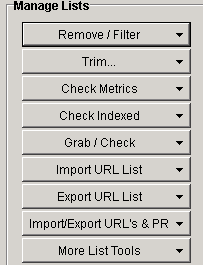
Remove/Filter - This area allows you to clean up any unnecessary URLs and sort your list into an order that you prefer. In this section you would remove your duplicate domains and URLs and can even remove URLs containing certain words, numbers of a certain length and can even remove sub domains.
Trim - You can trim any URLs to its root domain removing any sub pages within the site from your harvested list.
Check Metrics - This allows you to check the URL and domain metrics on Yandex.
Check Indexed - Once you've got a harvested URL's list it's a good idea to check if the site's are indexed by Google. You can also check if it's indexed on Yahoo or Bing.
Grab and Check - From here you can get quite a lot out of your URLs. You can grab anything from comments to images and emails.
Import URL List - You can import a list from either a file or paste it from a copied list of URLs to the harvester from your PC, this can also be added onto the existing URLs in the harvester.
Export URL List - There are quite a few file formats you can export too including text, excel, and html.
Import/Export URL's & PR - This allows you to import and export the URLs with their page rank.
More List Tools - Features like randomising the list's order are available in here. The next topic I will go onto explain is keywords in Scrapebox.
Keywords
Scrapebox has a few decent tools you can use for some keyword research.
Keyword Scraper
This tool allows you to enter a few keywords and the tool will look through the selected search engines and find keywords similar to the one's you've entered. First you need to click on the scrape button just underneath the keyword section, then you'll be presented with a window that looks like this:
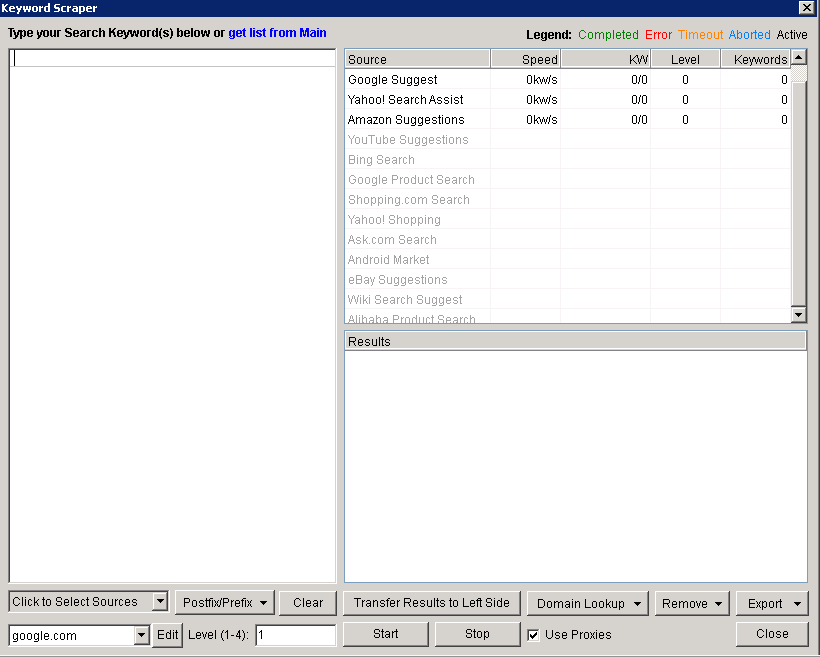
If you click on the menu at the bottom left you can select the search engines that you want the scraper to take it from. 
Now that you've selected your sources it's time to enter a few words that you want to scrape. I've typed in the words 'window repairs' and 'door repairs', clicked 'start' and up comes the suggested list.
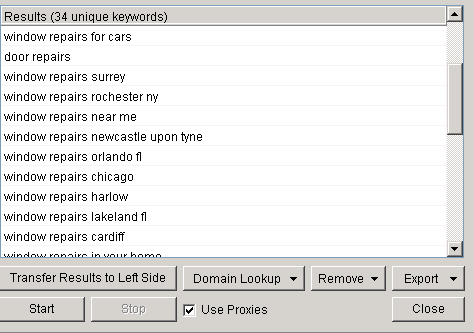
This is a list of 34 unique keywords that have been generated by Scrapebox. You need to click on the 'export' button to save the keywords to Scrapebox and then start the process over again with your new 34. You can keep doing this until you've finally got your ideal amount, now you can install the Google competition finder.
Google Competition Finder
This is another Add-on that is freely available on Scrapebox. With this you can check how many pages have been indexed by Google for each of your keywords. It is very useful in finding out how competitive each of your keywords are. To use this head to the 'Addons' tab and once you've installed it, load your keywords from Scrapebox onto it.
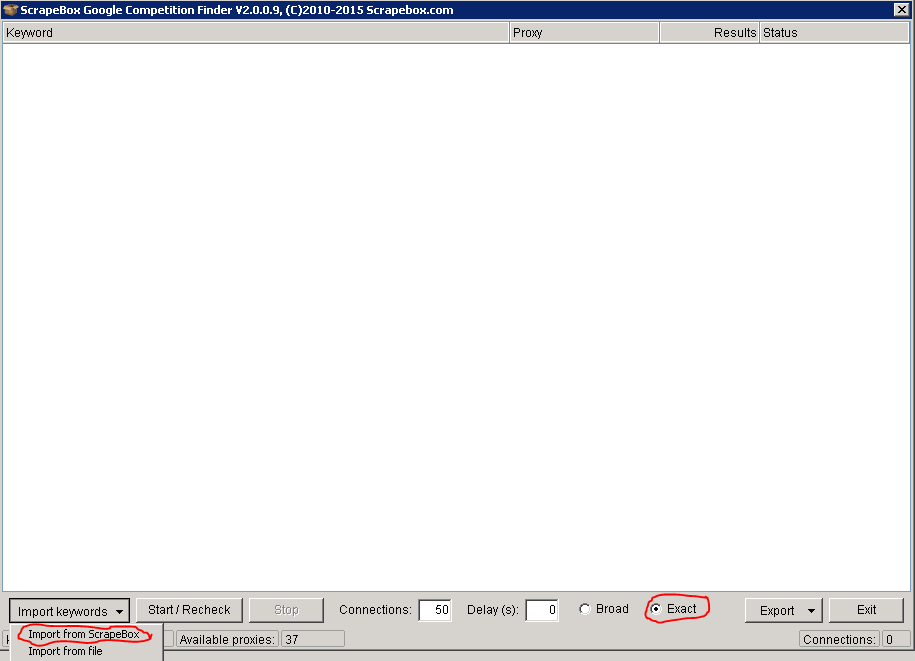
Now your keywords are ready, make sure that you check the box for 'exact match'. This means your keywords will use quotes to ensure the most accurate results. You can adjust the amount of connections you are using as well but I recommend about '10' to be safe. Once it's finished export the file as an excel file, this is done at the bottom right-hand site by clicking on the 'Export' button. Open up the excel file and sort the files from lowest to highest so you can get a better idea of how competitive each of your exact match keywords are. You could from here start to sort your keywords into high and low if you have a really high volume of words. The stats you gain from here aren't 100% accurate but they can give you a good indication of your Google competition. If the keywords number is also pretty low then this should give you a good knowledge of how easy it will be to rank them.
DomainsScrapebox TDNAM Scraper
This is a handy tool for finding expired domains. The only problem with this tool is that it takes all of its domains on from the 'Go Daddy' auction place. There is a whole marketplace throughout the web which leaves this tool kind of limited. Overall this is a decent tool to use if you don't want to pay for any other auctioning tool.
 To use this, import your keywords from Scrapebox and this tool will find any expired domains relating to these keywords. Once the scan is finished export your potential domains into a simple text file. With every domain you think about buying you should do your own manual checks to be sure that it is a domain worth buying. The problem using Scrapebox in that it still uses PR as its main metric. This used to be a great way to determine how powerful a site is but since the infamous penguin update everything has changed. PR hasn't been updated in years so you need to make sure that you check with tools such as Ahrefs and Majestic SEO to get a better idea before you commit to buying a domain. One tool it does have that can be quite useful is 'Scrapebox page authority'. This tool allows you to import all of the domains you collected earlier and can bulk check the page authority(PA) and Domain Authority(DA). Again this isn't the most important metric but it is useful.
To use this, import your keywords from Scrapebox and this tool will find any expired domains relating to these keywords. Once the scan is finished export your potential domains into a simple text file. With every domain you think about buying you should do your own manual checks to be sure that it is a domain worth buying. The problem using Scrapebox in that it still uses PR as its main metric. This used to be a great way to determine how powerful a site is but since the infamous penguin update everything has changed. PR hasn't been updated in years so you need to make sure that you check with tools such as Ahrefs and Majestic SEO to get a better idea before you commit to buying a domain. One tool it does have that can be quite useful is 'Scrapebox page authority'. This tool allows you to import all of the domains you collected earlier and can bulk check the page authority(PA) and Domain Authority(DA). Again this isn't the most important metric but it is useful.
To begin using this tool you have to head into the 'account setup' page where you will need to enter your access ID and your API information. You can get this information from the MOZ website with this link here: https://moz.com/products/api/keys Create a free Moz account, then click on the button that says "Generate Mozscape API key" and up will come your access id and secret key. (You have to be signed in to generate the key or it will just take you back to the overview page).
Now you paste this information into the 'account setup' page. You can add one of your proxies with the format looking like this access ID|secret key|proxy-details. There is a lot more that goes into finding powerful expired domains but for now this is just about what Scrapebox can do to filter out some of the useless domains before you go ahead with some proper research.
Where to place Links
Scrapebox can be used to find lots of link building opportunities. For example say you find a WordPress blogging site that is on page 4 or 5 for a keyword that you want to rank for, all you would do is create a profile, comment on a few articles and then place a link back to your own website. With Scrapebox you can use a few footprints that will scan a massive amount of sites with the specific platforms. To do this, harvest a few URLs using a list of keywords. Once the list is harvested, delete any of the duplicate URLs and open up the 'Scrapebox page scanner'. The page scanner will check each of your websites and display the platforms they use.
If you click on the 'edit' button at the bottom you can edit the footprints currently used. As you can see Scrapebox contains quite a few footprints by default which are simply a bunch of popular platform names. You could add any footprints you've created here as well, the footprints used here are not the same as your typical harvesting ones. The difference here is that the scanner searches the source code of all the sites looking for the footprints that will determine the platform being used. If you take the time to build some really good footprints you can get the best results finding any platform you want.
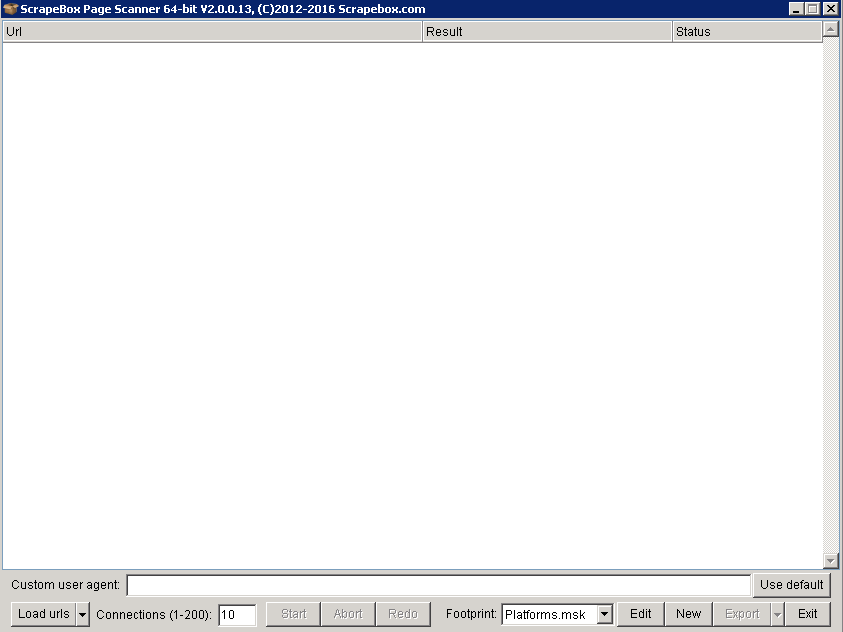
Load in your harvested keywords and start the process. The scan will run and the platforms will begin to show in the results tab. Once it's finished click on the export button and it will create a file separating your sites into each of their platforms. Once you've got the list your happy with, run the checks discussed in the previous topics like your page authority (PA) and domain authority (DA), along with doing your own additional external research to help narrow down what site's have the best link building opportunities.
Commenting
One thing about commenting using Scrapebox is it can leave obvious footprints if it's not done properly. Comment blasting like this should never be done on your money site, if you do any commenting like this it should be done on your third tier sites. When you harvest a list of site's you need to check the PR on each of the sites and how many outbound links the site has. Sites with low outbound links and high PR is what you are looking for. The problems can start to occur if you don't take time to have good spun comments and have enough fake emails you could leave a footprint. Once you have a decent set a URLs it's time to create your profiles. This is what you'll need:
- Spun anchors
- Fake emails
- Spun Comments
- List of sites to place links
Spinning Anchors
Use the keyword scraper to gather up a massive list from all of the sources and grab no less than 100. You can also add in some generic anchors and then save your file as a simple text file.
Fake Emails
The next step is creating a whole list of fake emails. Luckily Scrapebox has a great little tool for this exact purpose. Under the tools tab open up the 'name and email generator'.
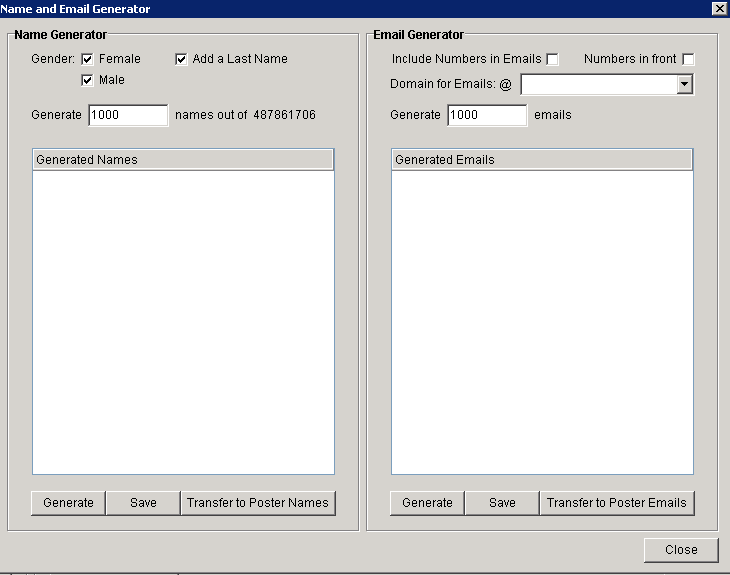
All you have to do here is change the 'generate' sections to about 20,000, check the box to include number in the email and change the 'Domains for Emails @' to one of the email services. Once you've done this, transfer your names and emails into the poster, then create another list of 20,000 emails but this time with a different email service.
Spinning Comment's
One of the easiest ways to get a massive list of spun comments is taking comments from similar sites in your niche and spinning those. Scrapebox has a feature available that allows you to grab comments from your harvested URLs.
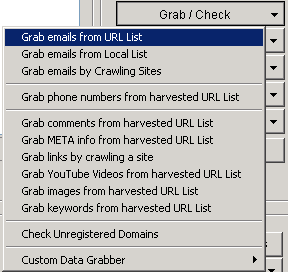
Click on the 'Grab/Check' button, then 'grab comments from harvested URL List'. This will tell you what platform each site is using and how many comments it's managed to scrape. Once it's finished save your list as a text file. Now you need to use a spinner for all of your comments. You can get article spinners out there from $50 a year. For comment spinning, you don't have to spend a fortune on one of these tools. One I would recommend thebestspinner.com. This will cost you $47 a year and is great for content spinning. Once you've got a tool you want to use, go through the settings which will be pretty straightforward. Once you have all of your spun comments save them as a text file and put them into the comments poster.
Websites - Create a list of sites that you want the backlinks for and name it websites.txt.
Auto Approve List - If you Google 'auto approve website lists' on Google you should get plenty of results, just grab one of these lists.
Settings - You need to adjust the timeout setting of the comment poster, to do this.

Click on the settings tab, head into the 'Connections, Timeout and Other Settings'. In the 'timeouts' section, you need to make the poster timeout time 120 seconds. This gives the poster enough time to load bigger sites with lots of comments.
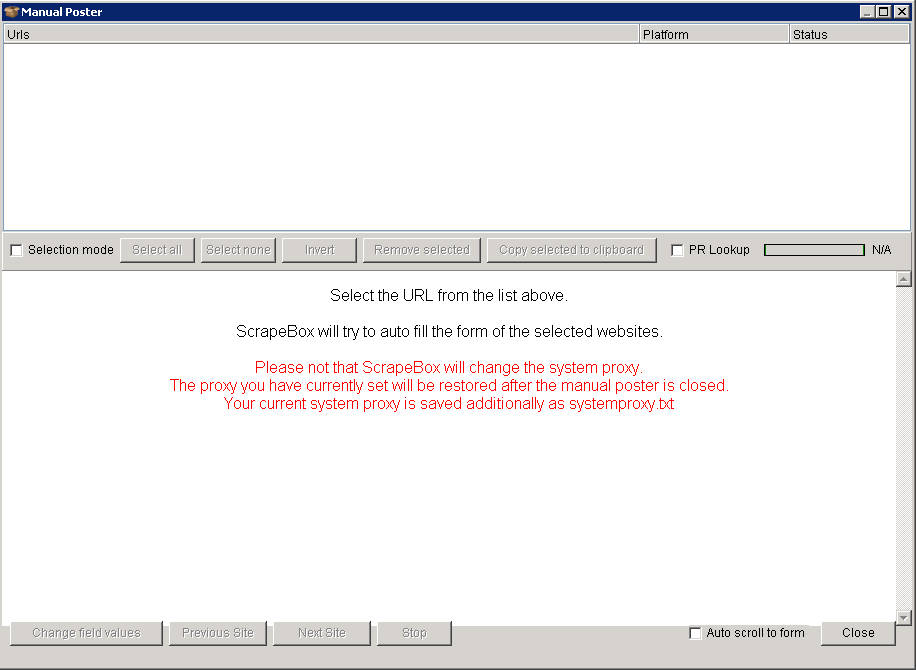
You can either choose the fast poster or manual poster. With manual poster you can go through each site and post comments individually. Once everything is set up click 'start poster'. Now you can work your way down the list and add each comment. Scrapebox will automatically fill in the form as best it can which is quite helpful in saving some time. Of course, if you decide to manually post it will take a lot more time but you will be able to decide exactly what is being posted on each site.
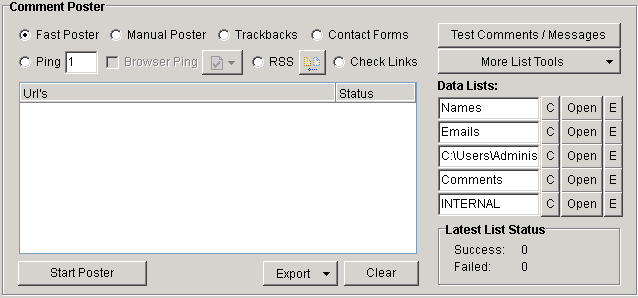
If you are using fast poster, check the box and let it run in the background.
Email Scraping
Scrapebox is great at scraping email addresses from harvested URL lists. First enter your footprint, add in all of your keywords and start scraping. Once you have your list delete any duplicate URL's. Now you head along to the option that says 'Grab/Check' and choose 'Grab emails from harvested URL List'
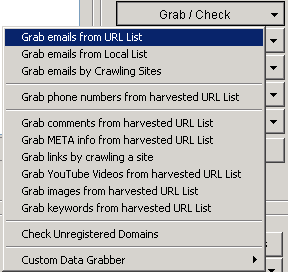
You can set it to take only one email per domain or grab all that's available (I recommended taking all of them as it may take one email from a user in the comments instead of an email relevant to the site). Click start and it will now begin going through each of the sites looking for any email addresses, when it's finished you can save all of them into a text file. You also have the option to filter out emails containing certain words before you save the file, which is great for narrowing down the search to your exact requirements.
Verifying Your Emails
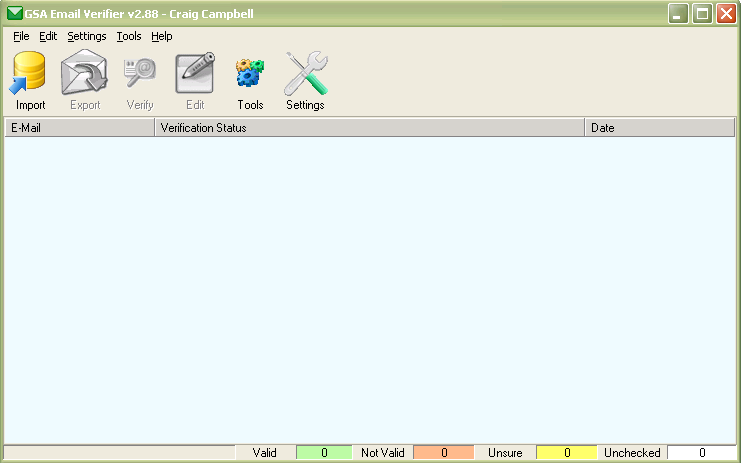
The next stage is to verify that they are all working emails. I do this with a tool called 'GSA email Verifier'. When all of your emails are ready you can import the text file into this tool, you can run a quick test or a full test on each email with the difference being the quick test will ping the server for a response and the full will try and connect with the server. You are best running a full test for more reliable results, once the results are finished you have the option to export only the emails that are working properly into a text file.
Add-ons
Scrapebox comes with a whole array of free add-ons. It's a good idea to familiarise yourself with them in case you ever need to use them. Go to the 'add-ons' tab and take a look through the list. Any plugins already installed show up in green and ones available are in red.
Backlink Checker - This plugin needs the Moz API information, once entered you can scan up to 1000 URL backlinks.
Alive Checker - The add-on allows you to check the status of each of the sites and will even follow any redirects, telling you where the final destination is.
Google Image Grabber - It allows you to scrape google images based on the keywords you've entered. You can either download these to your PC or preview them.
Link Extractor - This plugin allows you to extract both internal and external links from site's and save them to a text file.
Sitemap Scraper - The plugin will scrape a URL's XML or AXD sitemap instead of scraping Google's index pages. There is also a feature called 'deep crawl' which will scrape the URL's within the sitemap and any sites found within that.
Malware and Phishing Filter - This allows you to check sites for malware or if they have had it within the last 90 days. You can use your harvested URL list or load in a file. Any sites that contain malware can be filtered out to help keep your entire list risk free. There are also some great link building opportunities with this tool, if you do find malware on someone's site you can contact the webmaster and inform them of the problem. You could maybe even explain to them how to fix the issue or link them to an article that will. A lot of the time you might find that they will be willing to link to your website. You probably shouldn't ask for a link but it's entirely up to you how you approach the situation.
Audio Player - Just a simple audio add on that is available for entertainment.
Chess - The program is simply a playable chess game.
Port Scanner - This plugin allows you to check all your active connections, it's useful for monitoring your connections if any problems occur.
Bandwidth Meter - Checks your upstream and downstream speed.
Broken Links Checker - An add-on that checks your list of URL's and extracts all of its links. Once this is done it will check to see if these links are dead or alive.
Fake PR Checker - This add on works hand in hand with the TDNAM scanner, it will bulk check all of your sites PR values and tell you which ones are real and which are fake.
Google Cache Extractor - Will allow you to check the Google cache date of each URL and save it as a .txt file.
Social Checker - This will bulk check social metrics such as twitter, Facebook, LinkedIn, Google+. You can export these into many different formats like .csv, .txt, .xls etc.
Whois Scraper - It will pull up all of your site's Whois data, such as registrars name, email and domain expiration date.
DoFollow Test - This will check a bulk list of URLs backlinks and will determine which are do follow links and no follow links.
Rapid Indexer - You will be able to submit your sites to various other sites such as Whois. This will help you index all of your sites a lot faster onto Google.
Article Scraper - This will find articles from directories based on the keywords you enter, you can then save them onto your computer with a simple text file.
Anchor Text Checker - You can enter your domain into this tool along with the URL's of sites that link back to you. This will then take the anchor text from each of your links and display them to you with a percentage of how much each occurs.
Mobile Site Tester - Instead of individually entering every page on your site, you can use the mobile site tester to automatically go through your pages and it will tell you if it has passed or failed along with scores for each of the attributes that factor in.
Redirect Check - This add on will bulk check the final destination your site's URLs.
Automator (Premium Plugin) - With this plugin, you can set up a lot of the features to automatically run without you there. It is quite simple to set up, all you need to do is double-click on the features you want to be automated to add it to the list. It will carry out the task at the top first working downwards, for example below is a picture of an email scrape I have set up. First you harvest the URLs, then delete duplicate domains and then grab the emails. I have put a delay on of a couple of seconds before it starts the process over again.
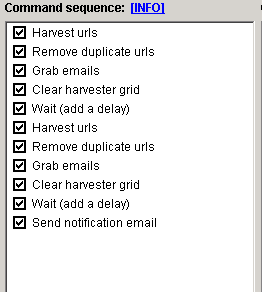
You can also set up an email notification at the end of the process, then go in and get the emails saved in the destination you choose. The command parameters section is the settings for the individual processes. Set them in any way that suits you. So you can go and get Scrapebox from www.scrapebox.com and i'm sure you will agree that it's the best money you are likely to spend on any one tool.